Three All-Nighters, One Loss, and Friday
How a hackathon loss sent me down a rabbit hole of fine-tuning, safety engineering, and binary embedding. Here's what I learned building Friday, a CLI tool that diagnoses network failures entirely on your own infrastructure.
Back in October, my teammate Ashutosh and I entered the OpenEuler Challenge hackathon at the University of Edinburgh. Three all-nighters. Twenty-five hours of coding and brainstorming. Two litres of caffeine and maybe twelve hours of sleep across the entire thing. At one point we left the hackathon mid-sprint to attend a JP Morgan event in Glasgow, came back, and kept going.
We built Samantha, an AI assistant that let you talk to your terminal in plain English instead of memorising cryptic commands. We made it to the final round. We didn’t win.
That stung for about a day. Then I looked at what we’d actually built through the sleep deprivation and the caffeine haze, and realised the interesting part wasn’t the file management wrapper. It was the execution layer underneath. We’d figured out how to make an LLM reason about system operations, chain them together, and self-correct when things went wrong. That was the seed.
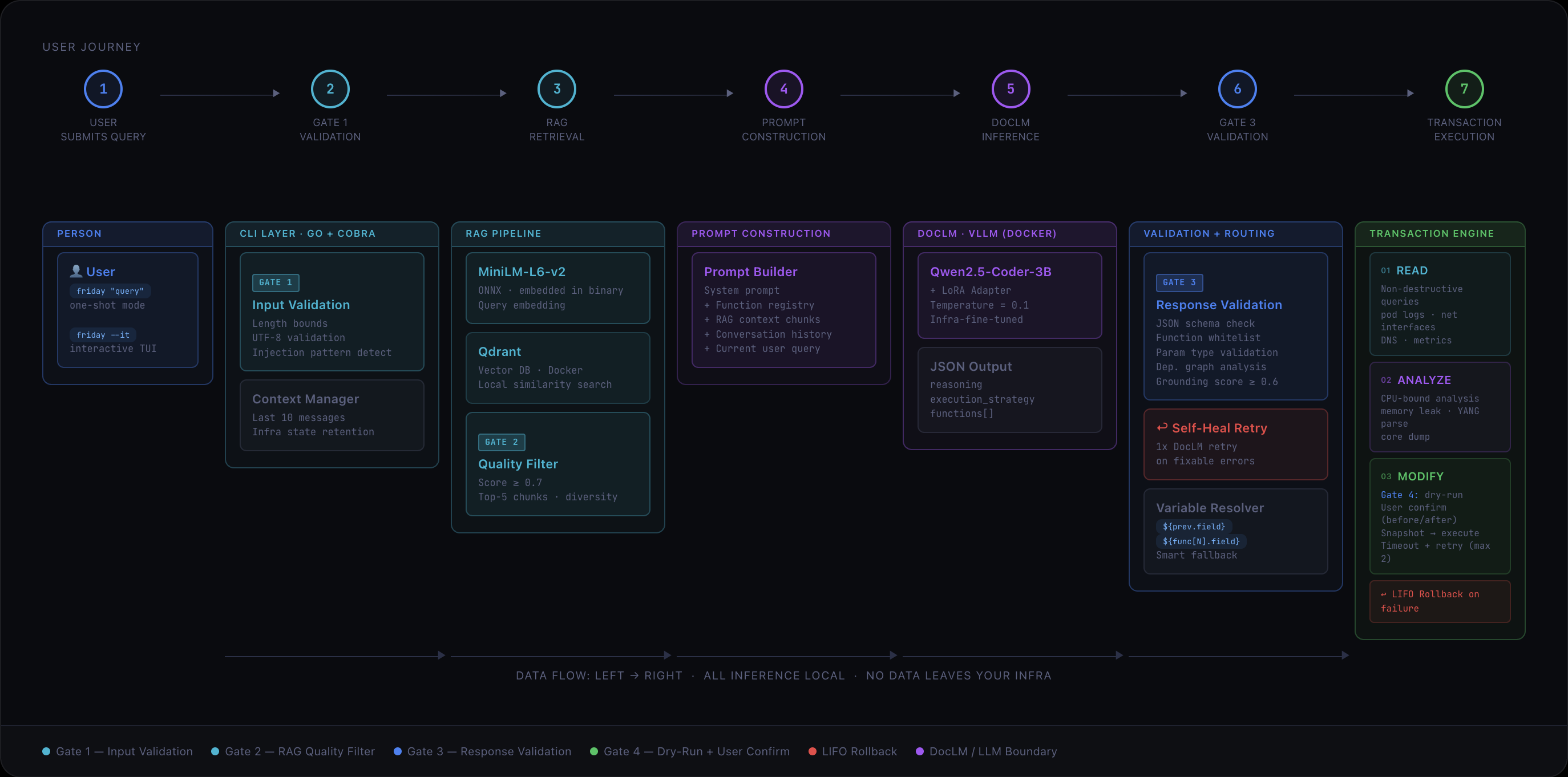
Over the next few months, we took that seed and grew it into Friday: a CLI tool backed by a fine-tuned LLM called DocLM that diagnoses and remediates real network failures, entirely on your own infrastructure, without a single byte of data leaving your perimeter.
This post isn’t a feature walkthrough. It’s about what I learned building it.
Starting Over Was the Hard Part
Samantha worked, but it was a hackathon project. The kind where you duct-tape things together at 2am and pray the demo holds. When we decided to keep going, we had a choice: polish what existed, or start from scratch with a clearer architecture.
We chose to start over. That was painful. We had working code. We had momentum. But we also had something worth carrying forward.
One of the best decisions from Samantha was that the LLM never generates commands. Instead, it selects from a fixed, whitelisted function registry. Every function has typed parameters, expected outputs, and defined side effects. The LLM’s job is to pick the right functions and chain them in the right order, not to invent new ones. We’d seen what happens without that constraint: plausible-looking commands with parameter names that don’t exist, the kind that would silently fail in production while the engineer thinks the fix was applied. That was scarier than a loud failure.
So the function registry survived the rewrite. Almost everything else didn’t. The real architectural shift for Friday was building a production-grade safety and execution layer around that core idea: the transaction engine, the validation gates, the self-healing inference loop. Samantha proved the concept. Friday had to make it trustworthy.
Fine-Tuning Taught Me Humility
We fine-tuned DocLM as a LoRA adapter on Qwen2.5-Coder-3B, training it on network telemetry scenarios: TCP/gRPC failure patterns, YANG model structures, kernel parameter docs, incident post-mortems.
The lesson that hit hardest for me: a 3B parameter model is smart enough to be dangerous and small enough to be wrong in ways that surprise you. Early versions would confidently chain three diagnostic steps together, get the first two right, and then reference a field from step one that didn’t exist in the output schema. Not a hallucination exactly, more like a typo in the model’s internal bookkeeping.
We could have tried to fix this with more training data. Instead, we built a self-healing loop: if DocLM outputs a bad variable reference, Friday catches it, sends the available fields back to the model, and retries once. One retry, no loops. If the second attempt fails, it aborts cleanly. This ended up being one of the most practically useful things in the entire system, and it came directly from watching the model fail in a specific, repeatable way. What I took from this: don’t paper over failure modes with data. Understand them, then engineer around them.
The Safety Engineering Took Longer Than the Features
Here’s something I didn’t expect: the safety layer takes longer to build than the features it protects.
We ended up with four validation gates between a user’s query and any network change. Input sanitisation. RAG retrieval quality filtering (we embedded MiniLM-L6-v2 as an ONNX model directly in the binary for zero-latency vector search against local docs). LLM response validation against a JSON schema with function whitelist checks and grounding scores. And a final dry-run gate where the engineer sees an explicit before/after diff and confirms manually.
Each gate exists because we found a specific way things could go wrong. Gate 2, the RAG quality filter, exists because we discovered that low-relevance context chunks don’t just reduce answer quality; they actively mislead the model. A chunk about DNS resolution scoring 0.4 similarity against a gRPC streaming question would cause DocLM to start diagnosing DNS when the actual problem was a kernel buffer overflow. Setting a hard floor of 0.7 and letting the pipeline refuse to proceed was better than letting it proceed with bad context.
The transaction engine follows the same philosophy. Every session runs in three phases: Read (non-destructive data gathering), Analyze (CPU-bound reasoning), Modify (changes with rollback). If anything fails during Modify, a LIFO rollback restores the exact prior state. We didn’t build this because it’s architecturally elegant. We built it because during testing, a half-applied sysctl change left a simulated system in a state that was worse than the original problem. Atomic transactions aren’t optional when your tool can modify kernel parameters.
Embedding the Embedding Model
One decision I’m particularly proud of: compiling MiniLM-L6-v2 directly into the Friday binary as an ONNX model.
The alternative was running it as a separate service. That means another container, another health check, another thing that can be down when you need it at 3am. By embedding it, the binary is fully self-contained. You get a single executable that handles both embedding and orchestration with zero startup latency for vector operations.
This is the kind of decision that doesn’t show up in feature lists but makes the difference between a tool that engineers actually reach for in an incident and one that sits unused because it’s too much friction to spin up.
What I’d Do Differently
If we started over today, two things stand out to me:
First, I’d push for evaluation infrastructure much earlier. For too long, our testing was “run it against five scenarios and eyeball the output.” A proper eval suite with regression tests for each gate would have caught issues faster and given us more confidence to iterate on the prompt and training data.
Second, I’d scope the function registry more aggressively at the start. We kept adding functions as we thought of useful diagnostics, and the registry grew in a way that made the LLM’s selection problem harder. A smaller, tighter registry with clear coverage boundaries would have produced better results earlier.
What Actually Happens When You Use It
A network engineer types something like friday "My gRPC stream is dropping packets, diagnose and fix". Friday reads live TCP state via ss -ti, checks gRPC health endpoints, measures stream latency, correlates the symptoms, identifies the root cause (often a buffer misconfiguration or flow control backpressure), proposes a specific fix, shows the before/after diff, and waits for confirmation.
The whole chain, from query to proposed fix, runs locally via vLLM. The engineer stays in their terminal. No context-switching to a dashboard. No copy-pasting logs into a chatbot.
Where It’s Going
The current release covers TCP, DNS, gRPC, kernel buffer tuning, core dumps, and the full transaction lifecycle. gNMI streaming telemetry and Kubernetes support are next.
Try It
If you know someone in networking or infrastructure who’s still hand-crafting sysctl invocations at 3am, share this with them. They deserve better.
Feedback, critical or otherwise, is welcome.